%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Best 150 Model Training and Deployment Tools of 2025

Search R1
Search-R1 is a reinforcement learning framework designed to train large language models (LLMs) capable of reasoning and calling search engines. Built upon veRL, it supports various reinforcement learning methods and different LLM architectures, enabling efficiency and scalability in tool-augmented reasoning research and development.
Model Training and Deployment
39.2K

Genprm
GenPRM is an emerging process reward model (PRM) that improves computational efficiency during testing through generative reasoning. This technology provides more accurate reward assessments when handling complex tasks and is suitable for applications in various machine learning and artificial intelligence fields. Its main advantages are the ability to optimize model performance with limited resources and reduce computational costs in practical applications.
Model Training and Deployment
39.5K

Arthur Engine
Arthur Engine is a tool designed to monitor and govern AI/ML workloads, leveraging popular open-source technologies and frameworks. The enterprise version of this product offers enhanced performance and additional features such as customized enterprise-grade safeguards and metrics, aiming to maximize AI's potential for organizations. It effectively evaluates and optimizes models, ensuring data security and compliance.
Model Training and Deployment
39.7K

Factorio Learning Environment
Factorio Learning Environment (FLE) is a novel framework built on the game Factorio, used to evaluate the capabilities of large language models (LLMs) in long-term planning, program synthesis, and resource optimization. As LLMs gradually saturate existing benchmark tests, FLE provides a new open-ended evaluation approach. Its importance lies in enabling researchers to gain a more comprehensive and in-depth understanding of the strengths and weaknesses of LLMs. Key advantages include open-ended challenges with exponentially increasing difficulty, and two evaluation protocols: structured tasks and open-ended tasks. This project was developed by Jack Hopkins et al., released as open source, free to use, and aims to promote research by AI researchers on the capabilities of agents in complex, open-ended domains.
Model Training and Deployment
50.8K

Light R1
Light-R1 is an open-source project developed by Qihoo360, aiming to train long-chain reasoning models through curriculum-style supervised fine-tuning (SFT), direct preference optimization (DPO), and reinforcement learning (RL). This project achieves long-chain reasoning capabilities from scratch through decontaminated datasets and efficient training methods. Its main advantages include open-source training data, low-cost training, and excellent performance in mathematical reasoning. The project background is based on the current training needs of long-chain reasoning models, aiming to provide a transparent and reproducible training method. The project is currently free and open-source, suitable for research institutions and developers.
Model Training and Deployment
75.1K

Awesome LLM Post Training
Awesome-LLM-Post-training is a repository focusing on large language model (LLM) post-training methods. It provides in-depth research on LLM post-training, including tutorials, surveys, and guides. This repository is based on the paper "LLM Post-Training: A Deep Dive into Reasoning Large Language Models" and aims to help researchers and developers better understand and apply LLM post-training techniques. This repository is freely available and suitable for both academic research and industrial applications.
Model Training and Deployment
52.7K

Bytedance Flux
Flux is a high-performance communication overlap library developed by ByteDance, designed for tensor and expert parallelism on GPUs. Through efficient kernels and compatibility with PyTorch, it supports various parallelization strategies and is suitable for large-scale model training and inference. Flux's main advantages include high performance, ease of integration, and support for multiple NVIDIA GPU architectures. It excels in large-scale distributed training, particularly with Mixture-of-Experts (MoE) models, significantly improving computational efficiency.
Model Training and Deployment
65.4K
Firecrawl LLMs.txt Generator
The LLMs.txt generator is an online tool powered by Firecrawl, designed to help users generate integrated text files for LLM training and inference from websites. By integrating web content, it provides high-quality text data for training large language models, thereby improving model performance and accuracy. The main advantages of this tool are its simple operation and high efficiency, allowing for the quick generation of required text files. It is primarily aimed at developers and researchers who need a large amount of text data for model training, providing them with a convenient solution.
Model Training and Deployment
58.5K

Aot
Atom of Thoughts (AoT) is a novel reasoning framework that transforms the reasoning process into a Markov process by representing solutions as a combination of atomic problems. This framework significantly improves the performance of large language models on reasoning tasks through decomposition and contraction mechanisms, while reducing wasted computing resources. AoT can be used as an independent reasoning method or as a plugin for existing test-time augmentation methods, flexibly combining the advantages of different methods. This framework is open-source and implemented in Python, making it suitable for researchers and developers to experiment with and apply in the fields of natural language processing and large language models.
Model Training and Deployment
67.9K
AI21 Jamba Large 1.6
AI21-Jamba-Large-1.6 is a hybrid SSM-Transformer architecture base model developed by AI21 Labs, designed for long-text processing and efficient inference. This model demonstrates excellent performance in long-text processing, inference speed, and quality, supports multiple languages, and possesses strong instruction-following capabilities. It is suitable for enterprise-level applications that require processing large amounts of text data, such as financial analysis and content generation. This model is licensed under the Jamba Open Model License, allowing research and commercial use under the license terms.
Model Training and Deployment
66.8K

SRM
SRM is a spatial reasoning framework based on a denoising generative model, used for inference tasks on sets of continuous variables. It gradually infers the continuous representation of these variables by assigning an independent noise level to each unobserved variable. This technique excels in handling complex distributions and effectively reduces hallucinations during the generation process. SRM demonstrates for the first time that denoising networks can predict the generation order, thus significantly improving the accuracy of specific inference tasks. The model was developed by the Max Planck Institute for Informatics in Germany and aims to advance research in spatial reasoning and generative models.
Model Training and Deployment
46.6K
Fresh Picks
Deepseek V3/R1 Inference System
The DeepSeek-V3/R1 inference system is a high-performance inference architecture developed by the DeepSeek team, aiming to optimize the inference efficiency of large-scale sparse models. It significantly improves GPU matrix computation efficiency and reduces latency through cross-node expert parallelism (EP) technology. The system employs a double-batch overlapping strategy and a multi-level load balancing mechanism to ensure efficient operation in large-scale distributed environments. Its main advantages include high throughput, low latency, and optimized resource utilization, making it suitable for high-performance computing and AI inference scenarios.
Model Training and Deployment
54.1K
Profiling Data In DeepSeek Infra
DeepSeek Profile Data is a project focused on performance analysis of deep learning frameworks. It captures performance data of training and inference frameworks through PyTorch Profiler, helping researchers and developers better understand computation and communication overlap strategies and underlying implementation details. This data is crucial for optimizing large-scale distributed training and inference tasks, significantly improving system efficiency and performance. This project is a significant contribution from the DeepSeek team in the field of deep learning infrastructure, aiming to promote the community's exploration of efficient computing strategies.
Model Training and Deployment
46.1K
Fresh Picks
EPLB
Expert Parallelism Load Balancer (EPLB) is a load balancing algorithm for Expert Parallelism (EP) in deep learning. It ensures load balance across different GPUs through a redundant expert strategy and a heuristic packing algorithm, while utilizing group-constrained expert routing to reduce inter-node data traffic. This algorithm is significant for large-scale distributed training, improving resource utilization and training efficiency.
Model Training and Deployment
49.7K
Fresh Picks
Dualpipe
DualPipe is an innovative bidirectional pipeline parallel algorithm developed by the DeepSeek-AI team. By optimizing the overlap of computation and communication, this algorithm significantly reduces pipeline bubbles and improves training efficiency. It performs exceptionally well in large-scale distributed training, especially for deep learning tasks requiring efficient parallelization. DualPipe is developed based on PyTorch, easy to integrate and extend, and suitable for developers and researchers who need high-performance computing.
Model Training and Deployment
49.1K
Tensorpool
TensorPool is a cloud GPU platform dedicated to simplifying machine learning model training. It provides an intuitive command-line interface (CLI) enabling users to easily describe tasks and automate GPU orchestration and execution. Core TensorPool technology includes intelligent Spot instance recovery, instantly resuming jobs interrupted by preemptible instance termination, combining the cost advantages of Spot instances with the reliability of on-demand instances. Furthermore, TensorPool utilizes real-time multi-cloud analysis to select the cheapest GPU options, ensuring users only pay for actual execution time, eliminating costs associated with idle machines. TensorPool aims to accelerate machine learning engineering by eliminating the extensive cloud provider configuration overhead. It offers personal and enterprise plans; personal plans include a $5 weekly credit, while enterprise plans provide enhanced support and features.
Model Training and Deployment
306.6K
Mlgym
MLGym is an open-source framework and benchmark developed by Meta's GenAI team and the UCSB NLP team for training and evaluating AI research agents. By offering diverse AI research tasks, it fosters the development of reinforcement learning algorithms and helps researchers train and evaluate models in real-world research scenarios. The framework supports various tasks, including computer vision, natural language processing, and reinforcement learning, aiming to provide a standardized testing platform for AI research.
Model Training and Deployment
52.2K
Flexheadfa
FlexHeadFA is an improved model based on FlashAttention, focusing on providing a fast and memory-efficient accurate attention mechanism. It supports flexible head dimension configuration, significantly enhancing the performance and efficiency of large language models. Key advantages include efficient GPU resource utilization, support for various head dimension configurations, and compatibility with FlashAttention-2 and FlashAttention-3. It is suitable for deep learning scenarios requiring efficient computation and memory optimization, especially excelling in handling long sequences.
Model Training and Deployment
48.3K
Fresh Picks
Flashmla
FlashMLA is a high-efficiency MLA decoding kernel optimized for Hopper GPUs, specifically designed for variable-length sequence services. Developed using CUDA 12.3 and above, it supports PyTorch 2.0 and above. FlashMLA's primary advantages lie in its efficient memory access and computational performance, achieving up to 3000 GB/s memory bandwidth and 580 TFLOPS computational performance on H800 SXM5. This technology is significant for deep learning tasks requiring large-scale parallel computing and efficient memory management, especially in natural language processing and computer vision. Inspired by FlashAttention 2&3 and the cutlass project, FlashMLA aims to provide researchers and developers with a highly efficient computational tool.
Model Training and Deployment
53.3K
Moba
MoBA (Mixture of Block Attention) is an innovative attention mechanism specifically designed for large language models dealing with long text contexts. It achieves efficient long sequence processing by dividing the context into blocks and allowing each query token to learn to focus on the most relevant blocks. MoBA's main advantage is its ability to seamlessly switch between full attention and sparse attention, ensuring performance while improving computational efficiency. This technology is suitable for tasks that require processing long texts, such as document analysis and code generation, and can significantly reduce computational costs while maintaining high model performance. The open-source implementation of MoBA provides researchers and developers with a powerful tool, driving the application of large language models in long text processing.
Model Training and Deployment
51.1K
KET RAG
KET-RAG (Knowledge-Enhanced Text Retrieval Augmented Generation) is a powerful retrieval-augmented generation framework enhanced with knowledge graph technology. It achieves efficient knowledge retrieval and generation through a multi-granularity indexing framework, such as a knowledge graph skeleton and a text-keyword bipartite graph. This framework significantly improves retrieval and generation quality while reducing indexing costs, making it well-suited for large-scale RAG applications. Developed in Python, KET-RAG supports flexible configuration and extension, catering to the needs of developers and researchers seeking efficient knowledge retrieval and generation.
Model Training and Deployment
67.9K
Fresh Picks
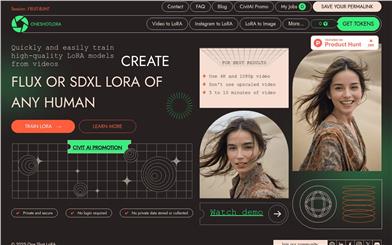
One Shot LoRA
One-Shot LoRA is an online platform focused on rapidly training LoRA models from videos. It leverages advanced machine learning technology to efficiently convert video content into LoRA models, providing users with a fast and convenient model generation service. The primary benefits of this product are its ease of use, no login requirement, and privacy protection. It does not require users to upload private data, nor does it store or collect any user information, ensuring the confidentiality and security of user data. This product is mainly aimed at users who need to quickly generate LoRA models, such as designers and developers, helping them quickly obtain the necessary model resources and improve work efficiency.
Model Training and Deployment
59.3K
English Picks
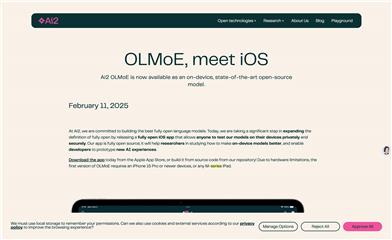
Olmoe App
OLMoE, developed by Ai2, is an open-source language model application aimed at providing researchers and developers a fully open toolkit for conducting AI experiments on-device. The app supports offline operation on iPhone and iPad, ensuring complete privacy for user data. Built upon the efficient OLMoE model, it maintains high performance on mobile devices through optimization and quantization. The open-source nature of the application makes it a vital foundation for the research and development of the next generation of on-device AI applications.
Model Training and Deployment
54.1K
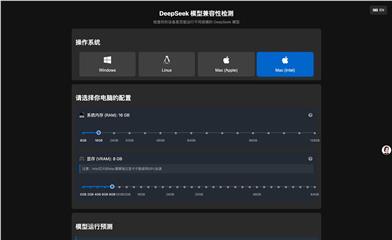
Deepseek Model Compatibility Checker
The DeepSeek Model Compatibility Checker is a tool for evaluating whether a device can run different sizes of DeepSeek models. By assessing the device's system memory, video memory, and other configurations alongside the model's parameters and precision requirements, it offers users predictions on model performance. This tool is significant for developers and researchers in selecting the right hardware resources for deploying DeepSeek models, helping them understand device compatibility in advance to avoid operational issues due to insufficient hardware. The DeepSeek model itself is an advanced deep learning model widely used in fields such as natural language processing, known for its efficiency and accuracy. Through this detection tool, users can better leverage the DeepSeek model for their project development and research.
Model Training and Deployment
112.9K
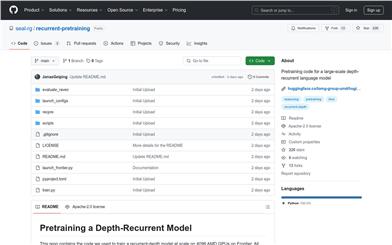
Recurrent Pretraining
This product consists of a pretraining codebase for large-scale deep recurrent language models, developed in Python. It is optimized for AMD GPU architecture, enabling efficient operation on 4096 AMD GPUs. The core strength of this technology lies in its deep recurrent architecture, which significantly enhances the model's inference capabilities and efficiency. It is primarily aimed at researching and developing high-performance natural language processing models, especially in scenarios requiring large-scale computational resources. The codebase is open-source and licensed under the Apache-2.0 License, making it suitable for academic research and industrial applications.
Model Training and Deployment
45.5K
Steev
Steev is a tool specifically designed for AI model training, aimed at simplifying the training process and enhancing model performance. It automatically optimizes training parameters, provides real-time monitoring of the training process, and offers code reviews and suggestions to help users complete model training more efficiently. One of Steev's main advantages is its ease of use, requiring no configuration, making it suitable for engineers and researchers aiming to improve model training efficiency and quality. Currently in a free trial phase, users can experience all its features at no cost.
Model Training and Deployment
46.6K
Kolosal AI
Kolosal AI is a tool for training and running large language models (LLMs) on local devices. By streamlining the processes of model training, optimization, and deployment, it enables users to leverage AI technology efficiently on local hardware. The tool supports various hardware platforms, provides fast inference speeds, and offers flexible customization capabilities, making it suitable for a wide range of applications from individual developers to large enterprises. Its open-source nature also allows users to conduct secondary development according to their specific needs.
Model Training and Deployment
67.9K
Chinese Picks

MNN
MNN is a deep learning inference engine open-sourced by Alibaba's Taobao technology platform, supporting popular model formats such as TensorFlow, Caffe, and ONNX, while being compatible with commonly used networks like CNN, RNN, and GAN. It achieves exceptional optimization of operator performance and fully supports CPU, GPU, and NPU, maximizing device computing power and widely applied in over 70 AI applications within Alibaba. MNN is recognized for its high performance, ease of use, and versatility, aiming to lower the threshold for AI deployment and promote edge intelligence development.
Model Training and Deployment
69.0K
Llasa Training
LLaSA_training is a speech synthesis training project based on LLaMA, aimed at enhancing the efficiency and performance of speech synthesis models by optimizing training and inference computational resources. This project leverages both open-source datasets and proprietary datasets for training, supports various configurations and training methods, and offers high flexibility and scalability. Its main advantages include efficient data processing capabilities, strong speech synthesis effects, and support for multiple languages. This project is suitable for researchers and developers in need of high-performance speech synthesis solutions, applicable to the development of intelligent voice assistants, speech broadcasting systems, and other scenarios.
Model Training and Deployment
53.5K

ASAP
ASAP (Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills) is an innovative two-stage framework aimed at addressing the dynamic mismatch between simulation and the real world, thereby enabling agile whole-body skills in humanoid robots. This technology significantly enhances a robot's adaptability and coordination in complex dynamic environments by pre-training movement tracking strategies and training a residual motion model with real-world data. Key advantages of ASAP include efficient use of data, substantial performance improvements, and precise control over complex movements, providing new directions for future humanoid robot development, especially in scenarios requiring high flexibility and adaptability.
Model Training and Deployment
49.7K
- 1
- 2
- 3
- 4
- 5
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.4K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.4K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.0K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M